
Chapter 5
Floating on Oceans.
“ It’s like I’m reading a book, and it’s a book I deeply love, but I’m reading it slowly now so the words are really far apart and the spaces between the words are almost infinite. ”
― Samantha, Her
This essay covers a series of amazing collaborations and leaps of creativity.
Machine learning programs broadly fall into two categories, detection/classification or generative. Algorithms like faceAPI and poseNet that I had worked with in previous projects are primarily detection models. Those models had led me to ways of thinking that were non-creative, judgmental, strict, conservative, and mean-spirited in nature. I did not trust the biographies and histories of them, the ideas behind and controlling them, and I did not trust that they could be used for anything worthwhile. They seemed to lead to diminishing and critical spaces, towards a type of control and structuring that I find to be antithetical to a creative, trusting, and caring collaboration. The other broad type of generative algorithm is almost exactly the opposite. It is wild, massive, complex, free, and untamed.
Working with generative machine learning was something entirely new. I did not know what I was looking at most of the time. I deployed a high-level machine learning algorithm, filled it up with modern graphic design and film examples, and got lost in what it created with those inputs. The generative aspect of machine learning does something like creativity, but a version of creativity that makes the word seem almost absurd to use. It is creative, like waves in the ocean are creative. But it is also full of agency, as waves in the ocean are full of agency. Machine learning does something that I can tangentially refer to as creative and not as an insult; I truly don’t have the vocabulary or knowledge to fully describe what is happening. I do know that it is not like other tools I have encountered. It is not like the beauty I can find in outputs of advanced math or the surprise and delight at a randomly juxtaposed pair of cut-up images in a collage. There is something that feels awesome, profound, exciting, overwhelming. And really, really big.

In 1993 I saw an art show that featured the effects of what would later come to be referred to as the Anthropocene. The measurable, “unnatural” impacts that humans have had on the world. One image showed the decayed remnants of a water bird of some sort that had ingested large amounts of plastic. The bird’s body, now reclaimed mainly by the surrounding environment and the rough shape of the bird in a pile of plastic that will outlive everyone. Some of these images have stuck with me for my entire life, including a series of photographs printed with a film that had been developed in the waters of Lake Ontario. A photography student, Jeremy Lynch, developed the photos in heavily polluted areas of the lake water in downtown Toronto. These projects were my first (sort of) realization or exposure to seeing and thinking about a network that did not center around humans, or me, almost at all. The network of agents at play in the waters of Lake Ontario’s Toronto shores existed without any consideration of me. The chemicals and currents, the temperatures and international trade agreements, the rusting ships in the water, the closing auto plants across the lake in Detroit—they all interacted on various scales in various ways in networks of action and agency that I was only a small part of, if at all. It was like a speculative poem about the complex relationships of these nonhuman actors, with the photographer (Lynch) as only a small part of his project.
The way I understand neural networks to function is like this. I provide a data set to the algorithm, such as a series of photos of myself. In some of the pictures I have my hand raised, in some I don’t. The algorithm detects differences in those images (hand or no hand), and then it determines a measurable contrasting aspect (again, hand/no hand). I can then show the program a new image it has never seen of me, and it will try and determine if my hand is raised or not. What it is actually measuring is in a black box that I don’t understand, but for this example, the algorithm can be thought to be seeing an aspect of the image that is along one dimension. The hands in the new images are either up or down. The machine learning models that are used in generative adversarial networks are in an n-dimensional space that is 512 parameters or 512D. The computer science of it all is beyond my understanding, but I gather that the computer is able to consider the various datasets it is being trained on in a way that is considerably more complex than I am able to do. What it is doing inside of that black box is an area of research the people are working on explaining, with the idea that it would be best if we had an idea about how this all worked. But this is like exploring and explaining the oceans; they are vast and complex and maybe only understandable in metaphor.
In the book What Algorithms Want by Ed Finn, interactions with machine learning are described with various metaphors of a person floating in the ocean. A person can swim on its surface, dive under that water briefly, or float on its surface in a boat. In doing so, the person can interact with its surface (or near-surface); they can smell and taste it, they can see the color of the water and the waves cresting and falling around them, but they can only interact with a very small aspect of the ocean directly. The rest, the vastness and unknowable teeming mass of it, has to be understood through metaphor.
The scale is awesome. Awesome in the staggering way. An object that defies simple descriptions and that can only be seen through a lens of metaphor. The speed with which this ocean moves is equally humbling. A universe of possibilities made and unmade in spaces of time so narrow that we can’t experience them as discrete packets. The speed and complexity of the algorithmic work of generative AI machines is staggeringly fast. When the technologies and algorithms of High-Frequency trading (HFT) are explored, researchers find that the programs are mostly not doing anything. The speed at which they do the work of the stock trading is so fast that they are hard to detect when seen at a human scale. Near the end of the 2013 film Her by Spike Jonze, the AI Samantha says to Theodore:
“It’s like I’m reading a book, and it’s a book I deeply love, but I’m reading it slowly now so the words are really far apart and the spaces between the words are almost infinite. I can still feel you and the words of our story, but it’s in this endless space between the words that I’m finding myself now. It’s a place that’s not of the physical world—it’s where everything else is that I didn’t even know existed. I love you so much, but this is where I am now. This is who I am now. And I need you to let me go. As much as I want to, I can’t live in your book anymore.”
This speculative agency of the machine in Her gives another view and set of metaphors about interaction with an ocean, about the vastly different ways we might interact with the machines (but also maybe how we might imagine we interact with almost everything.) The spaces between the words, like the “down-time” of the HFT algorithms, give us a way to understand the scale of the complexity, scope, and possibility of these tools.
Working with the generative machine learning algorithms helped me to take leaps of creativity and imagination into spaces I had not seen, or thought to look for, before.
Generative Adversarial Networks (GANs) — developed in 2014 by Ian Goodfellow — are a type of machine learning model that uses two sub-models to train against each other. One of the models attempts to create something new that can trick the second model’s authentication, the other tries to test if the object is real or fake. They work back and forth, refining the quality of the fake and of the test over and over. The parameters of the creation and of the testing are enormous and for the most part not understandable by humans. These tools are very complex, but a few WYSIWYG style applications have been developed recently. My early projects working with GANs used the tools developed by RunwayML that make the process of GAN development a lot easier.
I created three main projects with GANs at this stage in my thesis work. The systems I used for these early generative machine learning projects required a data set to train on. The initial data would be used by the testing sub model to learn what sorts of parameters it should look for. The creative sub model would create an image (it usually starts with a sort of grainy and blurry color gradient of random colors and intensities) to try and get it past the testing model. Developing the dataset is a very labor intensive task. Ideally the training set is a structurally similar image with the same dimensions and roughly the same figure-ground relationship. The most famous of these data sets (used to create StyleGAN) is a large set of photos of peoples faces. They are all looking at the camera, the images are cropped in such a way that each person’s eyes are in the same location and their heads take up roughly the same amount of space in the square image. In my excitement I did not do a lot (any?) of this prep work. I wanted to see what the machines could do. I was still very sceptical of what was possible, but also curious and eager to test it out. To create my dataset I downloaded every photo from the website trendlist.org (this is referred to as “scraping” and is a legally dubious method for image gathering.) My intention was to explore what the algorithm could do with this varied dataset. Could it make something “good”? Would it generate new art that I would consider to be of value?










































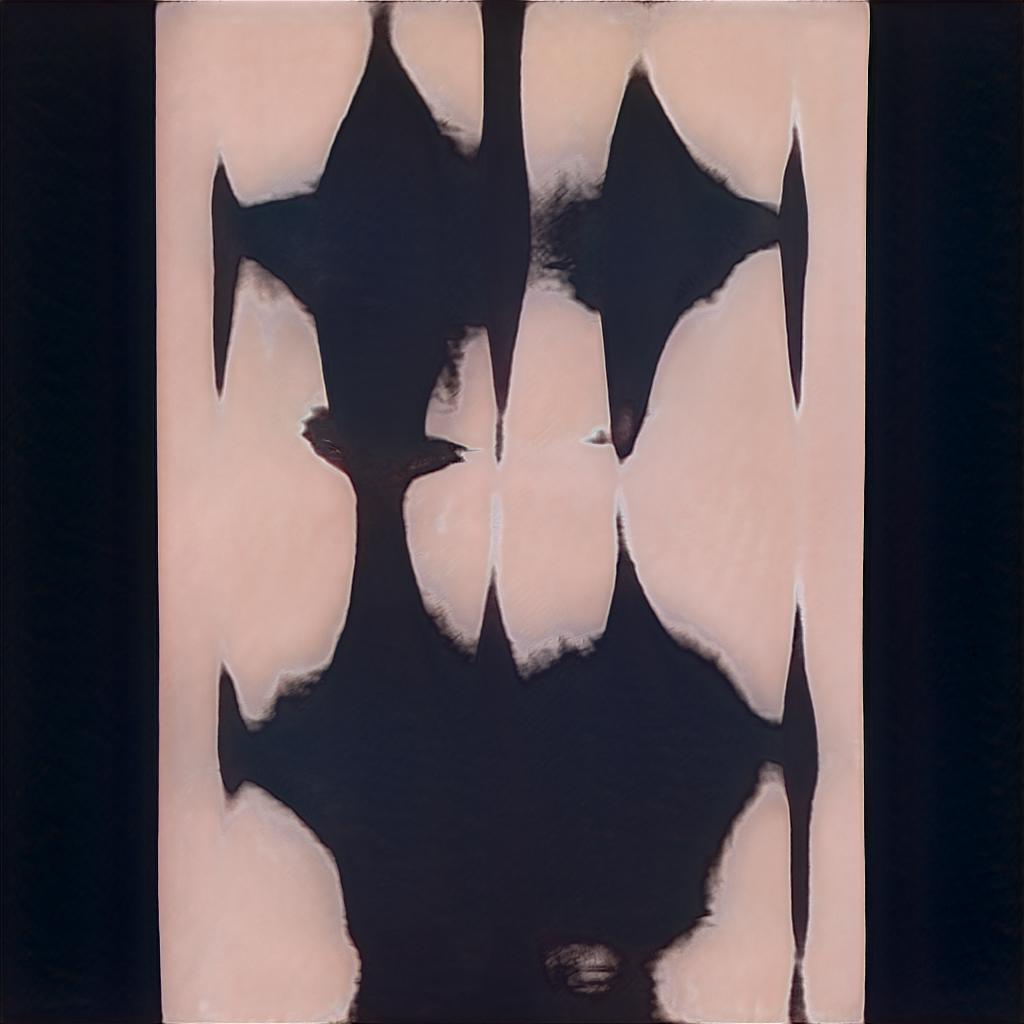








The outputs are bizarre, odd, ugly, beautiful; they are incredible and unexpected. The dataset was a mess. The images are all incredibly varied. Portrait poster, double-page spreads from zines, product shots photographed at low angles, various background colors and dimensions, very little was similar and nowhere near close enough to create what I imagined it would create. Luckily I was completely surprised by what it (we) made.
















































The second set was slightly more controlled. This time I scraped the dataset of images from the website typographicposters.com. I then did some post-processing on the images to make them more uniform, placing them on the same square background. In theory, these are all posters with type as the primary focus, all roughly the same page shape and figure/ground relationship in the image. To my eye—the eye of a person with graphic design training—these images, in some manner, had measurably repeating and contrasting elements. But the results were similarly strange. What I had hoped for or at least expected, what I imagined the GAN would develop, was some sort of new poster. Years ago I had developed another project that used the machine learning-based Content Aware Fill tool (available in Adobe Photoshop) to generate new parts of famous posters, and they had repeated various aspects of the original in interesting ways. The Adobe tool created new sections of a poster, based on elements of the whole. I had guessed that something similar would happen here. And maybe it did actually do that, but in a visual language that I could not understand. It found aspects of the posters to repeat, but they weren’t the aspects that for me made up a poster. In this my machine-collaborator began to reveal itself and its ideas, and it had different thoughts on poster design than I did.
In the third attempt I tightened my grip; I attempted to control the process as much as I possibly could. The previous attempts had felt like failures. They did not produce what I had anticipated. Yes they had made something new, but it was not what I wanted. This time I considered the best way to gather a large number of images that all looked very similar. My method in this was to use still images exported from a film that used a “locked down” camera. The Tom Waits and Iggy Pop scene from the 2004 film Coffee and Cigarettes, written and directed by Jim Jarmush, would provide the large image set I needed. The data set was as good as I could produce (still small, but very similar in content). I don’t know what I expected to see at the end of this process. What it produced was amazing, novel, and broken. It hinted at an understanding of the training data, or rather what it thought was important, but the output was completely alien to me. The system had worked beautifully, it had interpreted the data set and produced unique outputs. I now know that the failure was a failure of seeing on my part.
Looking back on them, these are bigger successes than I had originally understood them to be. My failure to recognize the value stemmed from my expectations about what this creative network was going to make. At this point, I wanted to have a lot of control over the outputs, to let them generate new materials, but inside of a very narrow space of what I would consider successful. But that’s because I was being a controlling controller, squeezing with more and more humancentric force; I did not know then what I know now about the creative value of a loosened grip.
The end.
︎︎
Next
Chapter 6 — Infinite Art Bot.